AI accuracy has been a known hindering feature for a long while now and according to major players in the industry it is not about to get better. While things are looking locked in, some raise the possibility to take these inaccuracies into account and make sure the user understands the limits to which an AI model can answer. Here we are not talking about hallucinations or whether or not a LLM will produce wrong information through bad interpretation. We speak of data intentionally created by the model in order to fill in a knowledge gap. Researchers are looking for a way to attest for these made-up data so that an AI will at least highlight unknown info and users are aware when they happen. It is highly urgent to do so as AI is now part of so many services and without talking about state surveillance, accuracy rating should be fully disclosed when interfering with the lives of many; even though British police says “the technology was accurate, with only one person being misidentified in 2024 out of more than 33,000 cases.”.
Staying in control Link to heading
Now, while we are having these discussions, we should note that AI tools cannot guarantee total privacy, as most platforms offer their services in exchange with training their models on user data. Anthropic’s Claude AI change in policy is one example of a product moving on with getting data from users and holding it for five years on either free or paid tiers (now optional, but it could quickly become unconditional if one wishes to continue using Claude AI). Therefore companies and states should do their most to move onto platforms using open source models (when possible). But what about individuals?
Best local LLM with decent preformative responses : Qwen3 30B Link to heading
Open source models have become increasingly good for most basic tasks, and can now even run on low-end hardware.
Such is the case of Qwen, a Chinese model that has been both increasingly accurate and popular among local LLM aficionados. The model is running on CPU-only with 32Gb of RAM and some have even succeeded in using Qwen3 on ARM with only 16Gb of memory. Indeed nowadays, AI server software programs have developed intelligent tools to allow the public to run models on low-end consumer hardware; for example using swap to load models, with works on either operating systems.
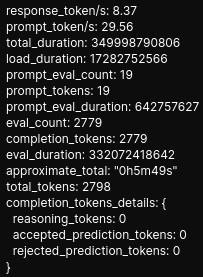
Here we get ~8 token/second which is very slow, but at least any information fed to the model is hosted locally.
Small PSA Link to heading
By the way, if anyone is using the same setup, meaning OpenWebUI coupled with Ollama to serve models, you might run into the following issue when running Qwen3:30b:
`500: llama runner process has terminated: exit status 2`
All I had to do is reboot and it magically disappeared.